The tech industry has been revolutionized in recent years by the advancements in machine learning and deep learning. The rising popularity of .ai domains is a clear indication of their impact.
Entering the world of machine learning can be intimidating for beginners, but mastering the basics is essential for exploring endless possibilities.
As machine learning becomes more prevalent, the potential applications across various industries are limitless. This article is designed to simplify machine learning and prepare you for insightful technical discussions.
What is Machine Learning?
Machine learning is a subset of Artificial Intelligence. Artificial Intelligence encompasses various techniques that aim to replicate human cognitive processes.
Machine learning focuses only on one key aspect: making machines learn.
Machine learning is the science of getting computers to make decisions without being explicitly programmed.
In the past decade, machine learning has given us self-driving cars, face recognition, chatbots, and many other useful applications. Machine learning is powering so many tools that we use on a daily basis.
How Does Machine Learning Work?
Machine learning employs algorithms to process enormous volumes of data and make inferences from it. By harnessing large datasets and advanced computing power, these algorithms can identify patterns and connections within the data.
For example, let's look at a simple dataset:
x = 1,2,3,4,5
y = 1,4,9,16,25
If you look at the above numbers, you'll see that the relationship between x and y is that y is a square of x (that is, y = x²).
In machine learning, the job of an algorithm is to find this function that defines the relationship between the input and output. Once this function has been established, it is easy to predict future values.
For example, if x is 10, y is 100.
Though this example is too simple, it should give you an idea of how machine learning models work.
Consider a complex dataset like predicting housing prices.
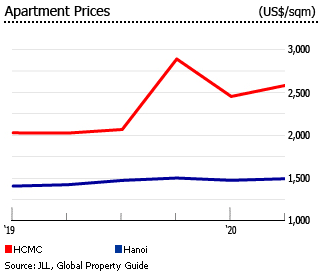
For predicting house prices in Ho Chi Minh City (HCMC) or Hanoi, you'd want to select statistical parameters that are relevant and influential in determining housing prices. Here are some:
- Area/Size of the Property: The size of the property (in square meters or square feet) is a fundamental factor influencing its price.
- Number of Bedrooms and Bathrooms: The number of bedrooms and bathrooms in a property often correlates with its size and thus affects its price.
- Location: Location is crucial in real estate. Factors like proximity to city center, public transportation, schools, parks, and amenities can significantly impact property prices.
- Year Built: The age of the property can affect its condition and desirability. Newer properties may command higher prices due to modern amenities and construction quality.
- Neighborhood Demographics: Characteristics of the neighborhood, such as income levels, crime rates, and population density, can influence property prices.
- Historical Price Data: Analyzing historical price data can provide insights into price trends and seasonality, helping to make more accurate predictions.
- Property Type: Whether the property is a house, apartment, or condominium can affect its price.
- Market Demand: Factors affecting market demand, such as economic conditions, interest rates, and housing market trends, should be considered.
- Features and Amenities: Special features like a swimming pool, garden, garage, or high-end appliances can add value to a property.
- Accessibility: Easy access to major roads, highways, and public transportation hubs can influence property prices.
- School District: Properties located in well-regarded school districts may command higher prices due to the perceived value of education.
- Condition of the Property: The overall condition of the property, including any renovations or upgrades, can affect its price.
- Property Tax Rates: Property tax rates can vary depending on the location and affect the overall cost of ownership.
- Housing Market Dynamics: Understanding supply and demand dynamics, housing inventory levels, and market competition is essential for accurate predictions.
- Regulatory Factors: Local zoning laws, building regulations, and property taxes can impact property prices and should be considered in the analysis.
If you have a dataset with thousands of these statistical parameters into your predictive model, you can build a more comprehensive understanding of the factors influencing house prices in HCMC and Hanoi. Machine learning algorithms can then be trained on these features to make accurate predictions based on new inputs.
Machine learning problems usually involve finding the relationship between the inputs and outputs to find the ‘hypothesis function’. In our earlier example, the hypothesis function was y = x².
Real-world hypothesis functions are much more complex than this. We then use that function to find answers for custom inputs.
In a nutshell, machine learning, in most cases, is advanced statistics combined with computational capacity. Today, machine learning powers technologies like facial recognition, sentiment analysis, and many others.
Types of Learning Algorithms
Let's explore the different types of challenges that arise when working with machine learning. To begin with, there are various approaches to teaching machines.
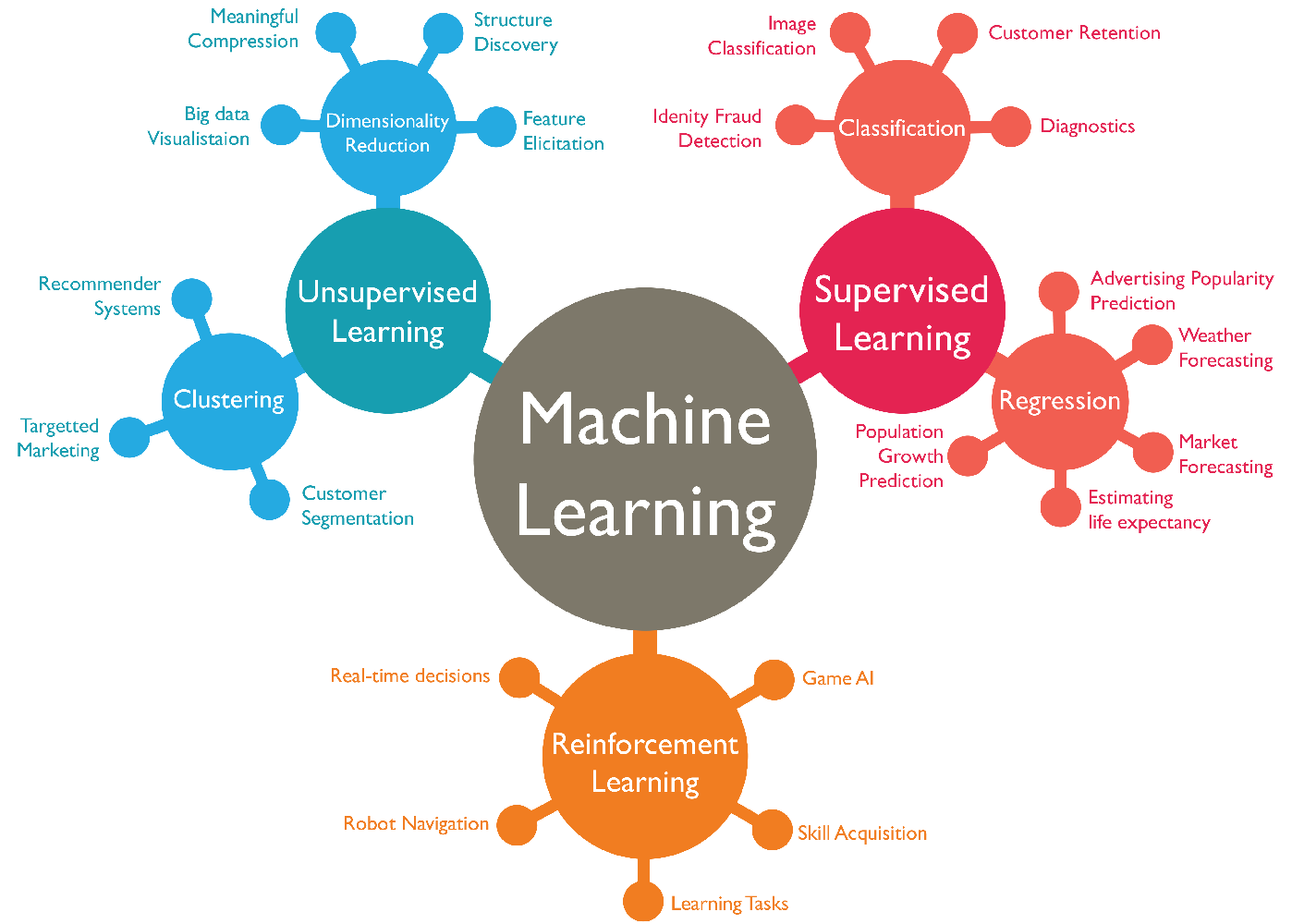
Supervised Learning
In supervised learning, you provide clear inputs to a machine learning algorithm. The algorithm knows what to learn from the data and the conclusions expected from it.
For example, for recognizing the difference between a cat and a dog, you train an algorithm with thousands of images. Each of these images will be labeled accordingly.
Once you run this data through the algorithm, the algorithm learns and understands the differences. Thus, it can predict, with reasonable accuracy, whether a new image is a cat or a dog.
Unsupervised Learning
Labeling data is important to build a supervised model. However, companies collect large datasets on a daily basis. Labeling these datasets to make the job of a machine learning model easier is not an elegant way to approach this problem.
This is where unsupervised learning comes in. You can use unsupervised learning algorithms to cluster data based on available attributes. This data can then be fed into supervised learning models to achieve higher prediction accuracy.
Unsupervised learning models are more challenging than supervised learning models. You can find more information and examples here, and you can learn more about important machine learning algorithms here.
Reinforcement Learning
No machine learning algorithm can guarantee complete accuracy. The accuracy of the algorithm varies depending on the dataset it is trained on.
This means that after you train an algorithm, there can be new datasets available. These datasets might have the potential to improve the accuracy of your model considerably.
Reinforcement learning is a technique that enables algorithms to evolve and improve while in use. These models can adjust and enhance their performance based on real-time data.
For example, a self-driving car can learn about a new type of terrain after it has traveled through that terrain. This will be taken into account by the self-driving car’s algorithm the next time it has to choose a route.
Types of Machine Learning Problems
Machine Learning problems can be classified into four subcategories based on the type of result you are looking for.
Classification
Classification models produce a result that belongs to a finite set. Examples of classification models include spam/not spam, 0 or 1 (binary classification), positive/negative/neutral, and so on.
Regression
Regression models produce results that belong to a range. Examples include predicting stock market prices, weather forecasting, and more. These are not limited to a finite set of values and hence are called regression problems.
Imagine you're trying to predict the height of a tree as it grows over time. You can't say exactly how tall it will be, but you can estimate a range. Regression models in machine learning work similarly. They don't give you an exact answer like "the tree will be 10 feet tall," but rather a range of possibilities, like "the tree will likely be between 8 to 12 feet tall."
Now, think about predicting stock market prices or forecasting the weather. These are situations where you can't predict an exact value, but you can estimate a range of possibilities. For example, you might say "the stock price could be between $50 and $60 tomorrow" or "there's a 70% chance of rain tomorrow." These types of predictions, where the result falls within a range rather than a specific value, are called regression problems in machine learning. They deal with continuous outcomes and are not limited to a fixed or finite set of values.
Clustering
Clustering is a key concept in unsupervised learning. Clustering helps you group data that have similar attributes. Once these groups have been established, it becomes easier to train them using supervised models.
Imagine you have a big basket filled with different kinds of fruits like apples, oranges, and bananas, but they're all mixed up. Now, your task is to organize them based on their similarities. Clustering in machine learning is like sorting these fruits into groups. You might put all the apples together, all the oranges together, and all the bananas together. This process helps you see which fruits are similar to each other.
Once you've grouped the fruits, it's like having baskets labeled "Apples," "Oranges," and "Bananas." With these organized groups, it becomes easier to teach someone else how to sort fruits. Similarly, clustering helps machine learning algorithms understand the patterns and similarities in data so that they can make better predictions or decisions in the future. It's like laying the groundwork before diving into more detailed analysis or training using supervised learning techniques.
Dimensionality Reduction
Dimensionality Reduction is another unsupervised learning technique. Using Dimensionality reduction, you can reduce a complex dataset with thousands of features into a simple one with maybe a hundred inputs.
Similar to clustering, dimensionality reduction is often used to reduce noise from large datasets before feeding them into supervised training models.
What is Deep Learning?

Deep learning is Machine learning on steroids.
There are many algorithms in machine learning. One that stands out is a Neural Network.
The difference between other machine learning algorithms and a neural network is that you can stack neural networks together — as many as you want.
This helps us solve complex problems like facial recognition and self-driving since these types of problems come with thousands of inputs in real-time.
When armed with the requisite data and computational power, neural networks can effectively tackle a variety of intricate problems with impressive accuracy.
Neural networks have been around for decades, but it was the availability of large datasets and computing power that bought them back to life. Now deep learning is one of the most exciting fields in the industry.
Why Do You Need Machine Learning?
Let's look at some popular machine learning solutions that we use every day.
Voice assistants

Have you ever thought about how Siri can understand and process your voice commands? The answer lies in machine learning. Nowadays, almost every smartphone comes with a voice assistant, thanks to the advancements in Natural Language Processing.
The big innovation now you can see in our assistant is LLM, now devices understand instead of just interaction
Even though it is hard for computers to understand natural language, thanks to machine learning, we have Alexa, Cortana, and Siri.
Product recommendations

Recommendation systems are a valuable tool for e-commerce businesses. By analyzing customer preferences and behavior, these systems can suggest relevant products, increasing the likelihood of repeat purchases.
Machine learning models can identify patterns in user data to make accurate product recommendations. This personalized approach enhances the shopping experience and boosts sales for online retailers.
The concept of recommendations extends beyond e-commerce, with platforms like Amazon, YouTube, and social media using similar algorithms to suggest content based on user interests.
Chatbots

Providing excellent customer support is crucial for the success of any business, especially for startups. As your customer base grows, so does the need for efficient support services.
Utilizing chatbots can significantly streamline customer interactions. By programming a chatbot to handle frequently asked questions, you can enhance the overall customer experience.
With chatbots, there is no need to hire additional customer service representatives or subject customers to long wait times. Businesses are leveraging the power of Machine Learning to save time and resources.
Spam filtering

Machine Learning has greatly enhanced spam filtering, allowing email services like Gmail and Outlook to efficiently detect and block spam messages.
These systems are designed to adapt and improve over time through reinforcement learning, becoming more accurate in identifying your preferences when you mark emails as spam.
Thanks to Machine Learning, our inboxes are now much cleaner.
Language translation

Imagine a world without Google Translate. Machine learning-driven language translation platforms are instrumental in saving businesses millions each year.
Before the era of machine learning, translation services were predominantly human-driven. With machine learning, you can effortlessly translate vast amounts of data into any language within minutes.
The process for train a Machine learning Model
Imagine you're teaching a friend how to bake a cake. You start by gathering all the ingredients like flour, sugar, eggs, and butter. This is like collecting data for your machine learning model. Then, you follow a recipe step by step, mixing the ingredients, pouring the batter into a pan, and baking it in the oven.
Training a machine learning model is similar. Instead of ingredients, you gather data like numbers and measurements. Then, you use an algorithm, which is like a recipe, to analyze the data and find patterns. The algorithm adjusts itself based on the data, just like you might adjust the amount of sugar or flour in your cake batter to get the right taste and texture.
After the model has been trained on the data, it's like your cake coming out of the oven. You can now use it to make predictions or decisions based on new data, just like you can serve your cake to your friends once it's baked. And just like you might tweak the recipe for your cake next time based on how it turned out, you can also refine and improve your machine learning model based on its performance.
Tools and Frameworks
Python is widely used for machine learning and deep learning due to its extensive libraries and frameworks. While other programming languages offer their own tools, Python remains the top choice for these tasks.
Check out some popular Python frameworks that can help you develop your next machine learning or deep learning project.
- Scikit-learn — Popular for machine learning problems. Great community support. Not suitable for complex deep learning models.
- Tensorflow — Most popular deep learning framework. Built by Google. Supports all complex deep learning models like CNNs and RNNs
- PyTorch — Built by Facebook, scalable, and offers high performance.
I recently wrote a blog post on popular deep learning frameworks if you are interested.
Conclusion
Machine learning is reshaping industries across the board, enabling groundbreaking progress. From elevating customer experiences to fueling innovation, the potential of machine learning is limitless.
--
Thang Pham - Innoria Founder & CEO